《삼국지》 단어 탐색기(Word2Vec)
“유비”와 “선주”의 차이는?

🔎 《삼국지》 단어 탐색기 소개
최근 “《삼국지》 단어 탐색기”라는 것을 만들어서 웹에 공개했습니다.
https://zyahan.blog/sanguozhi-word-explorer

진수의 《삼국지》와 배송지의 주석 한문 원문에 등장하는 한자와 고유명사의 쓰임을 컴퓨터에게 학습시킨 모델을 통해 특정 단어와 비슷한 단어를 찾아보는 도구입니다.
🤖 컴퓨터가 잡아낼 수 있는 단어의 의미
한국어를 사용하는 사람들은 “차”라는 단어와 “커피”라는 단어 사이에 비슷한 점이 있다는 사실을 알고 있습니다. 둘 다 음료의 명칭이기 때문입니다. 그런데 컴퓨터가 이 사실을 알 수 있을까요?
컴퓨터는 기본적으로 “차”와 “커피”의 사전적 의미를 모릅니다. 이들이 음료의 명칭이라는 사실은 더더욱 모릅니다. 사실 “음료”가 무엇인지조차 모릅니다.
그렇다면 컴퓨터는 무엇을 알 수 있을까요? 컴퓨터에게 사람들이 실제로 사용한 언어를 모아 놓은 자료를 주면, 컴퓨터는 “차”와 “커피”가 둘 다 “잔”, “마시다”와 함께 나오는 일이 많다는 패턴을 찾을 수 있습니다. 바로 이 패턴을 통해 컴퓨터는 “차”와 “커피”를 비슷한 단어로 인식할 수 있습니다.
- 차를 잔에 따라 마셨다.
- 커피를 잔에 따라 마셨다.
- ___를 잔에 따라 마셨다.
사실 사람도 비슷합니다. 가령 “고사도”라는 말을 처음 듣는다고 하더라도, “고사도를 잔에 따라 마셨다.”라는 문장을 접했을 때 고사도가 음료의 일종이라고 추측할 수 있습니다. “고사도”가 기존 음료 단어들처럼 “잔”, “마시다”와 함께 나타났기 때문입니다.
바로 이런 패턴을 찾아내는 도구로 Word2Vec 모델이 있습니다. Word2Vec 모델은 각 단어가 어떤 문맥에서 나타나는지 학습해서 단어를 벡터로 표현합니다. 단어를 벡터로 표현하면, 두 단어의 의미가 얼마나 비슷한지를 ‘코사인 유사도’라는 척도로 계산할 수 있습니다.
《삼국지》 단어 탐색기는 이 코사인 유사도를 이용해서 《삼국지》에 나타난 단어들의 의미를 비교할 수 있게 만든 도구입니다.
⚖️ 두 단어 비교 예시: “유비” vs. “선주”
《삼국지》 단어 탐색기를 활용해서 “유비”와 “선주”를 비교해 봅시다. 아시다시피 이 두 단어는 모두 유비를 가리킵니다. 하지만 《삼국지》 텍스트에서 두 단어의 쓰임은 상당히 다릅니다. 아래의 결과를 살펴봅시다.
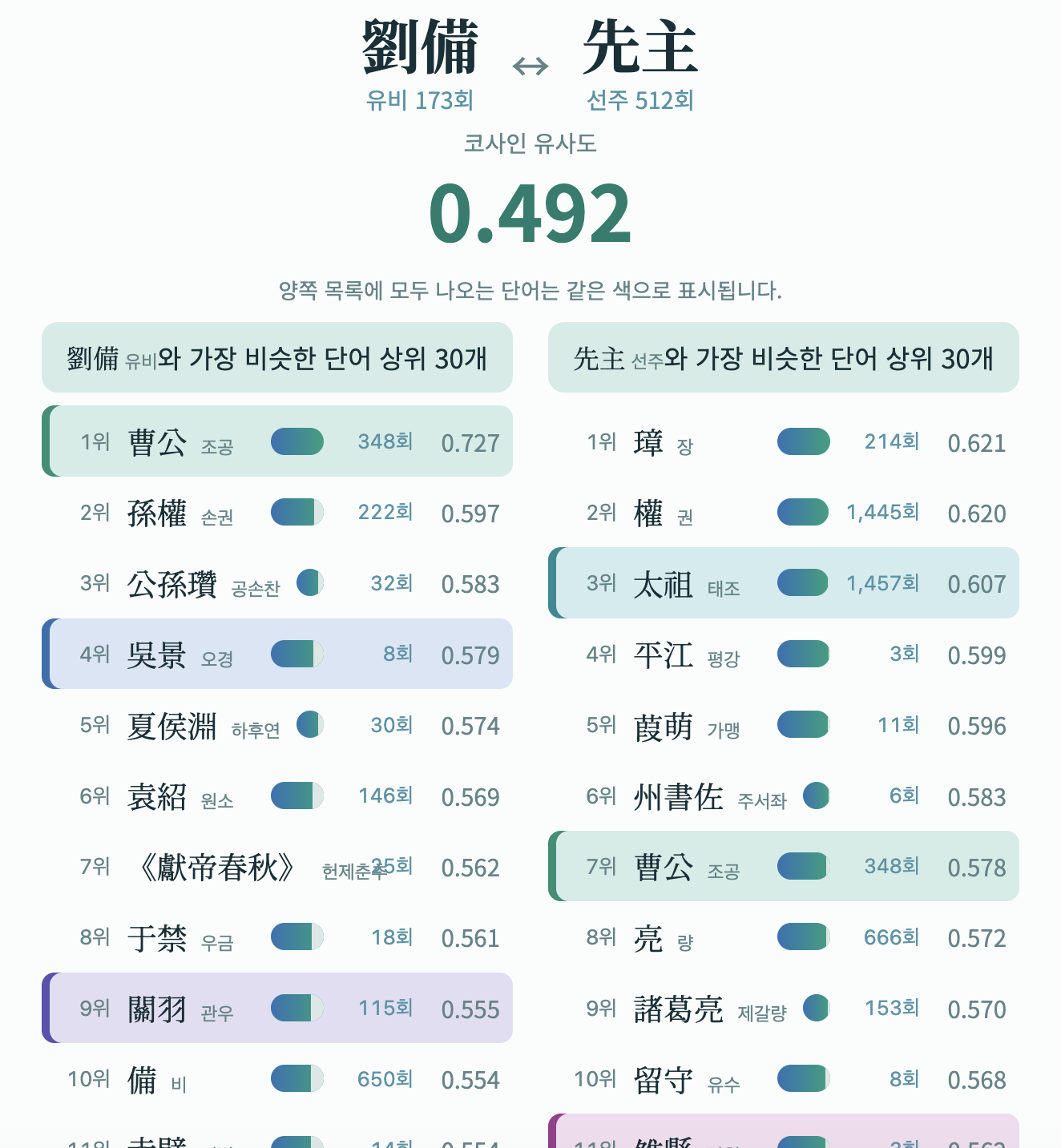
버전 1.5.0 기준으로, “유비”와 “선주” 두 단어의 코사인 유사도는 0.492입니다. 참고로 코사인 유사도는 1에 가까울수록 두 단어가 비슷하다는 뜻이고, 0.492면 높은 값이라고 하기 어렵습니다.1
《삼국지》 전체에서 “유비”와 비슷한 단어 1위는 조조를 가리키는 “조공”, 2위는 “손권”, 3위는 “공손찬”입니다. 반면 “선주”와 비슷한 단어 1위는 익주목 유장의 이름 “장”, 2위는 오나라 손권의 이름을 가리키는 일이 많은 “권”, 3위는 조조의 묘호 “태조”입니다. 조조와 손권이 공통적으로 등장하지만, 유비와 마찬가지로 불리는 방법이 두 목록에서 각기 다릅니다.
이 결과를 통해 우리는 같은 사람을 가리키는 각기 다른 칭호들이 실제로 서로 다른 문맥에서 쓰인다는 사실을 알 수 있습니다. 《삼국지》의 저자 진수는 ‘위진정통론’에 입각하여 조조와 그의 후예들을 황제의 일대기인 ‘기’에 실었고 유비와 손권의 경우 신하의 전기인 ‘전’에 실었습니다. 하지만 촉 출신이었던 진수는 유비를 손권보다 더 존중해서, 유비의 경우 이름을 쓰기보다 “선주”로 칭하기를 선호했습니다. Word2Vec 모델은 《삼국지》 텍스트에서 이 편향을 학습한 것입니다.
Word2Vec 모델에서 계산한 코사인 유사도 기준으로는 “유비”와 “조공”이 서로 비슷하고, “선주”와 “태조”가 서로 비슷합니다. 전자는 다른 진영에서 비교적 중립적으로 쓴 칭호고, 후자는 《촉지》와 《위지》 내에서 각기 유비와 조조를 개국 군주로 높인 칭호입니다. 전자와 후자의 차이가 코사인 유사도 수치로도 드러나는 셈입니다.
🕵️ 스파이 찾기 예시: 주유·노숙·여몽·육손 vs. 제갈량
또 다른 예시로 “주유”, “노숙”, “여몽”, “육손”, “제갈량” 다섯 단어를 비교해 봅시다. 주유, 노숙, 여몽, 육손은 모두 오나라의 도독이고, 제갈량은 촉나라의 승상입니다. 컴퓨터가 이들의 차이를 잡아낼 수 있을까요? 아래의 결과를 살펴봅시다.
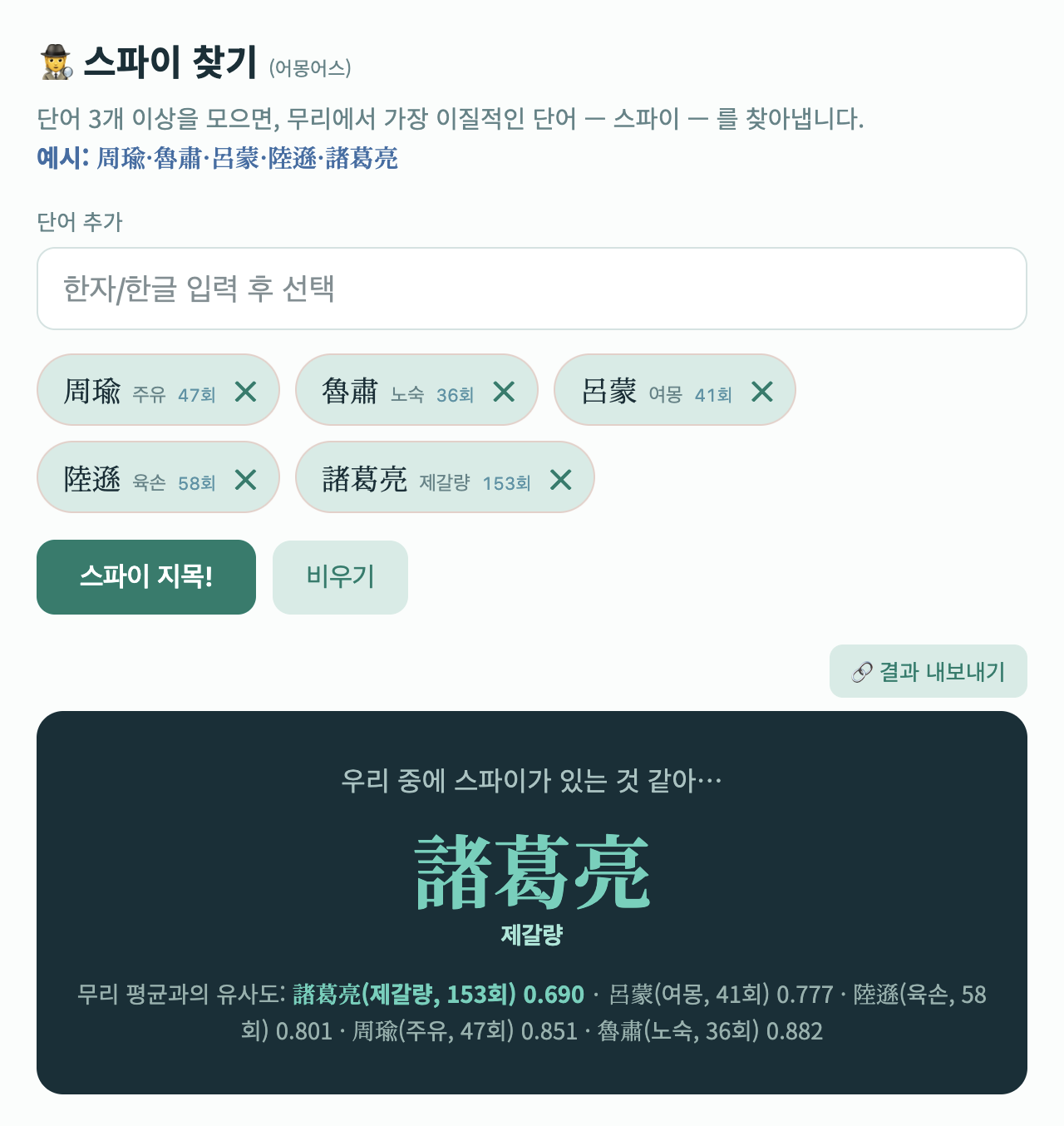
세 개 이상의 단어를 넣으면, 컴퓨터는 각 단어 벡터의 평균을 구합니다. 그리고 그 평균에서 가장 멀리 떨어진 단어를 ‘스파이’로 간주합니다. 위의 결과에서는 “제갈량”이 스파이로 잡혔습니다. 《삼국지》 텍스트에서 오나라 도독들의 성명이 서로 비슷한 패턴으로 쓰였고 제갈량은 다른 문맥에서 주로 쓰였다는 사실을 컴퓨터가 잘 학습했음을 알 수 있습니다.
⚠️ 주의사항
컴퓨터가 단어의 사용 패턴을 학습하기 위해서는 단어가 자료에 충분히 등장해야 합니다. 단어가 《삼국지》 텍스트에 출현한 횟수가 매우 적은 경우 모델이 제대로 학습하지 못했을 가능성이 높으므로, 해당 단어의 유사도는 신뢰하기 어려울 수 있습니다.
문의사항이나 오류 제보는 이 포스트에 댓글로 남겨 주세요.
주석
-
사실 절대적인 수치보다 중요한 것은 상대적인 비교입니다. 위의 결과에서 볼 수 있듯이, 아의 《삼국지》 Word2Vec 모델에서 “유비”와 가장 비슷한 단어는 “조공”으로 나타났습니다. “유비”와 “조공”의 코사인 유사도는 0.727로, “유비”와 “선주”의 유사도였던 0.492보다 훨씬 높습니다. 즉, “유비”는 《삼국지》에서 “선주”보다 “조공”과 더 비슷한 쓰임을 보였다는 뜻입니다. ↩
![11. 조조가 유비를 일컫는 말의 변화: ‘명사군’부터 ‘짚신가게 새끼’까지 [🔒 무료 미리보기]](/assets/images/cards/cao-cao-card.jpeg)